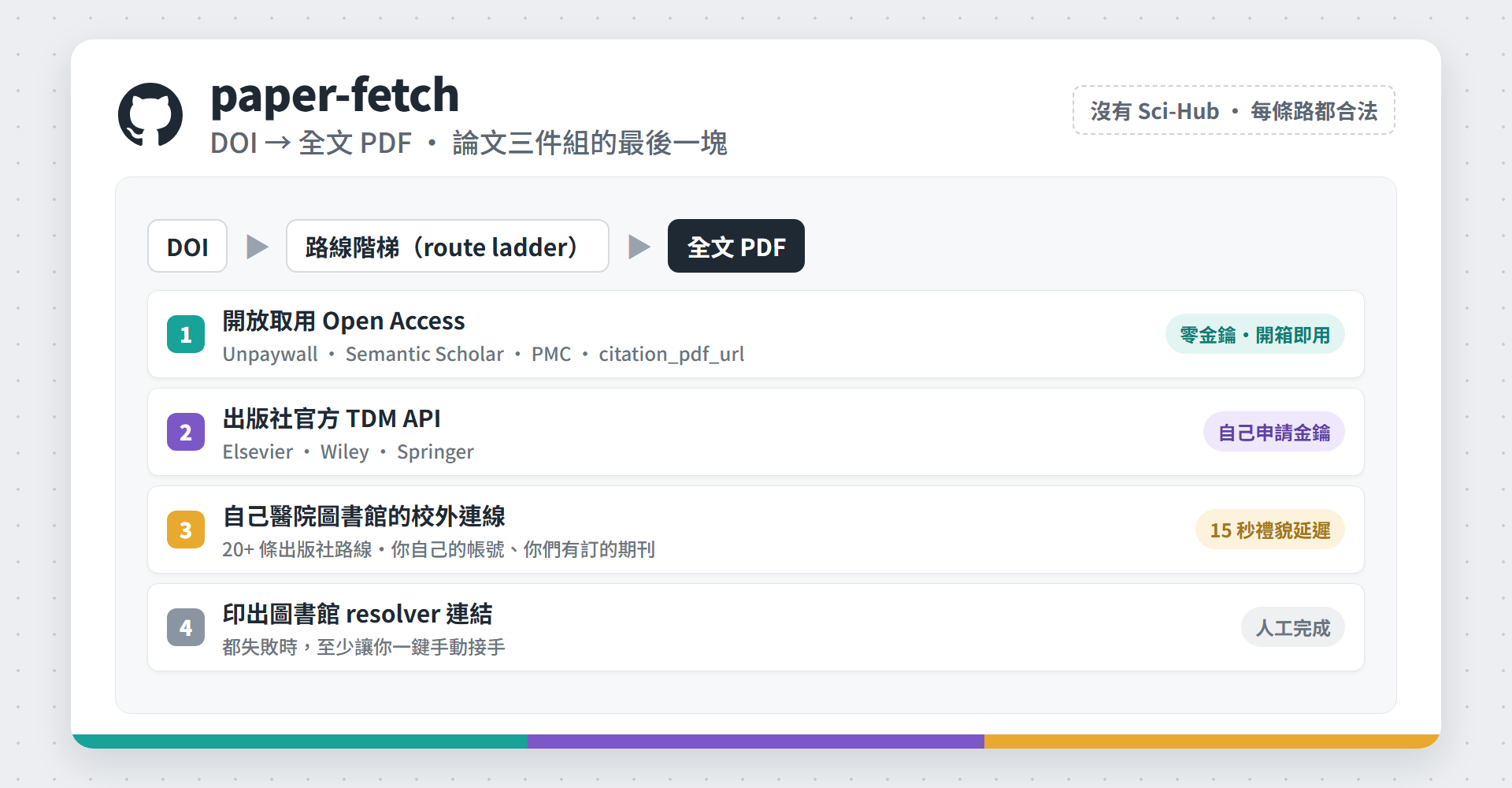
論文三件組的最後一塊:paper-fetch,給它一個 DOI,它自己去把全文抓下來
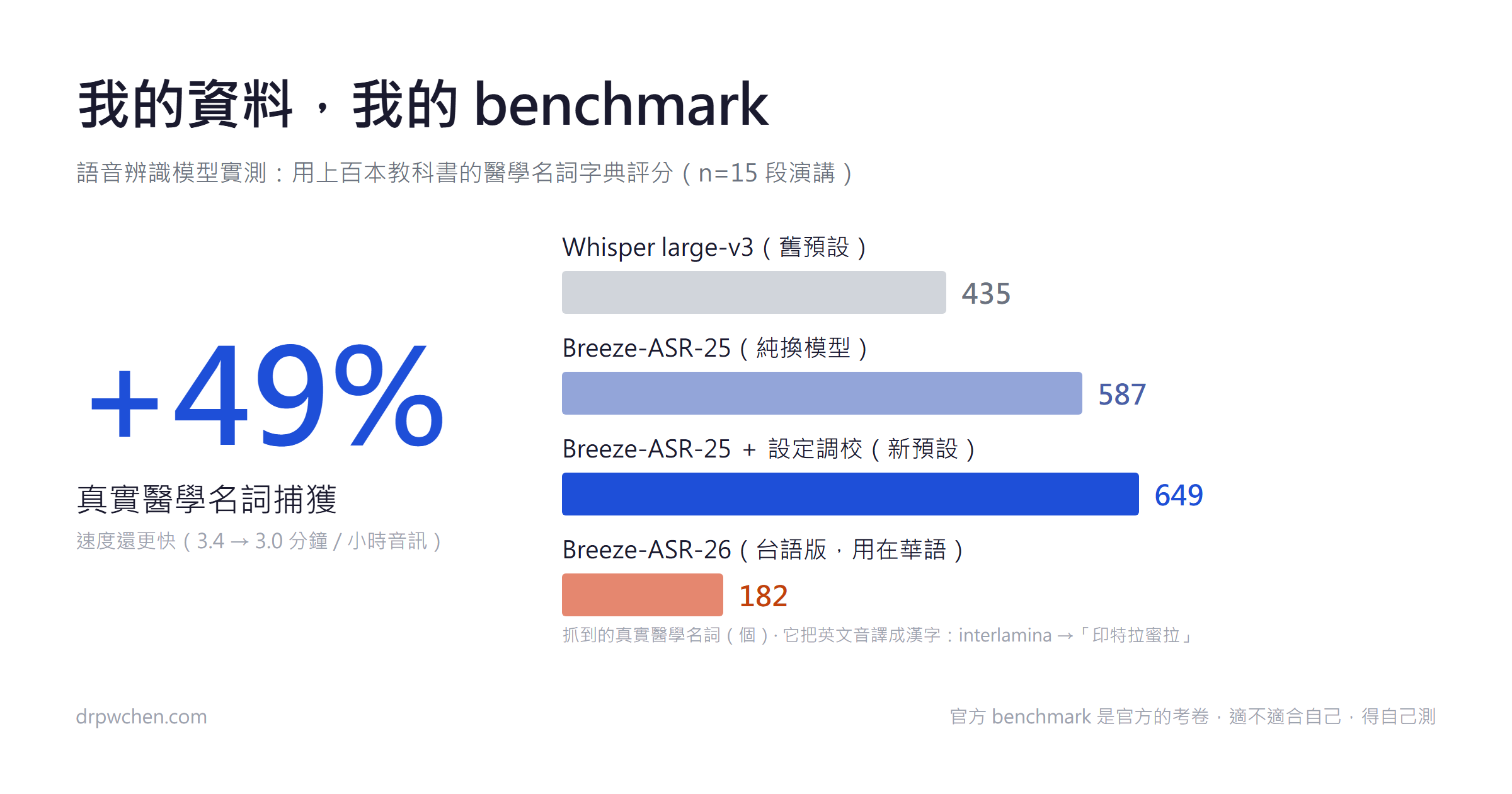
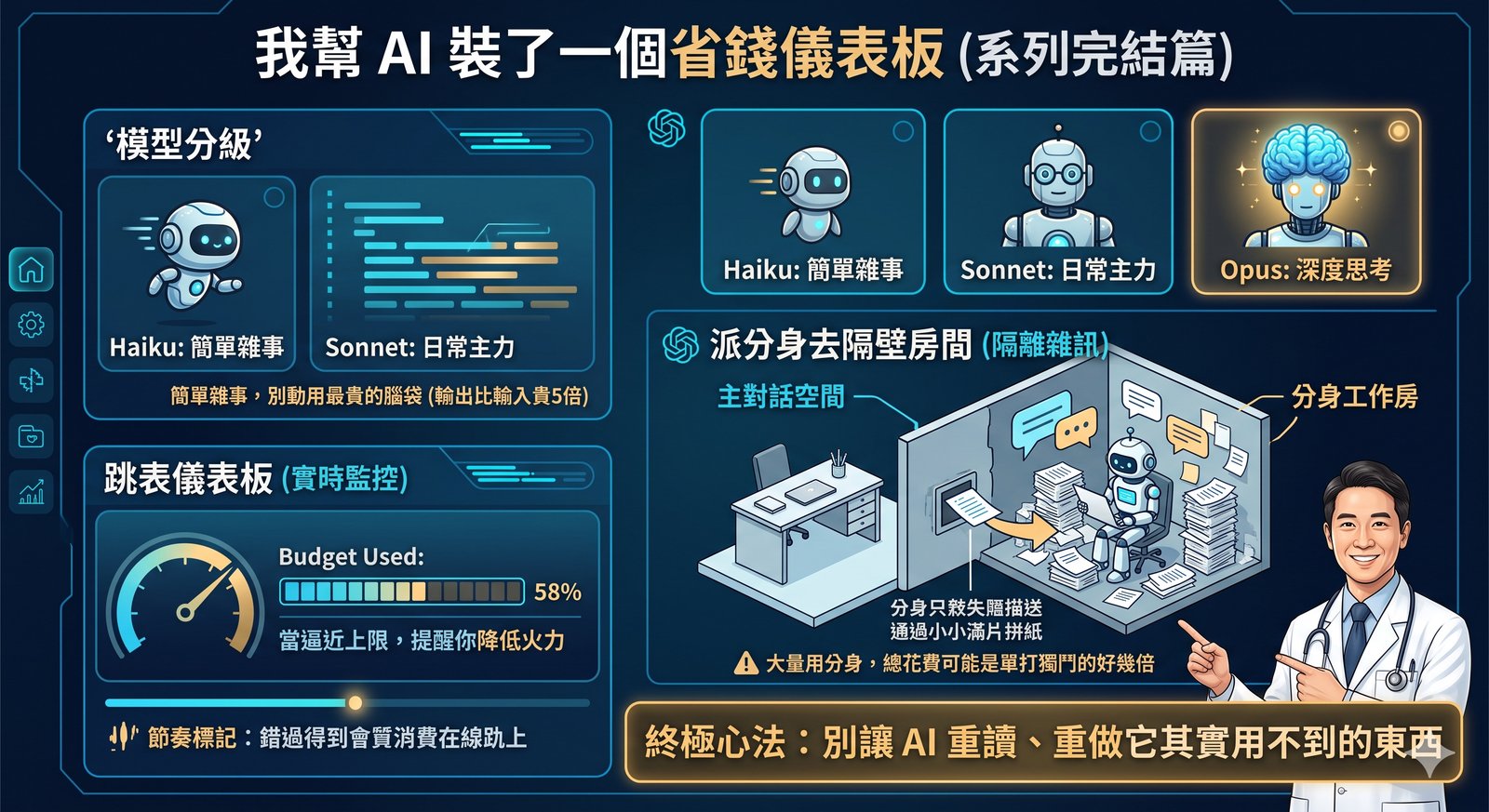
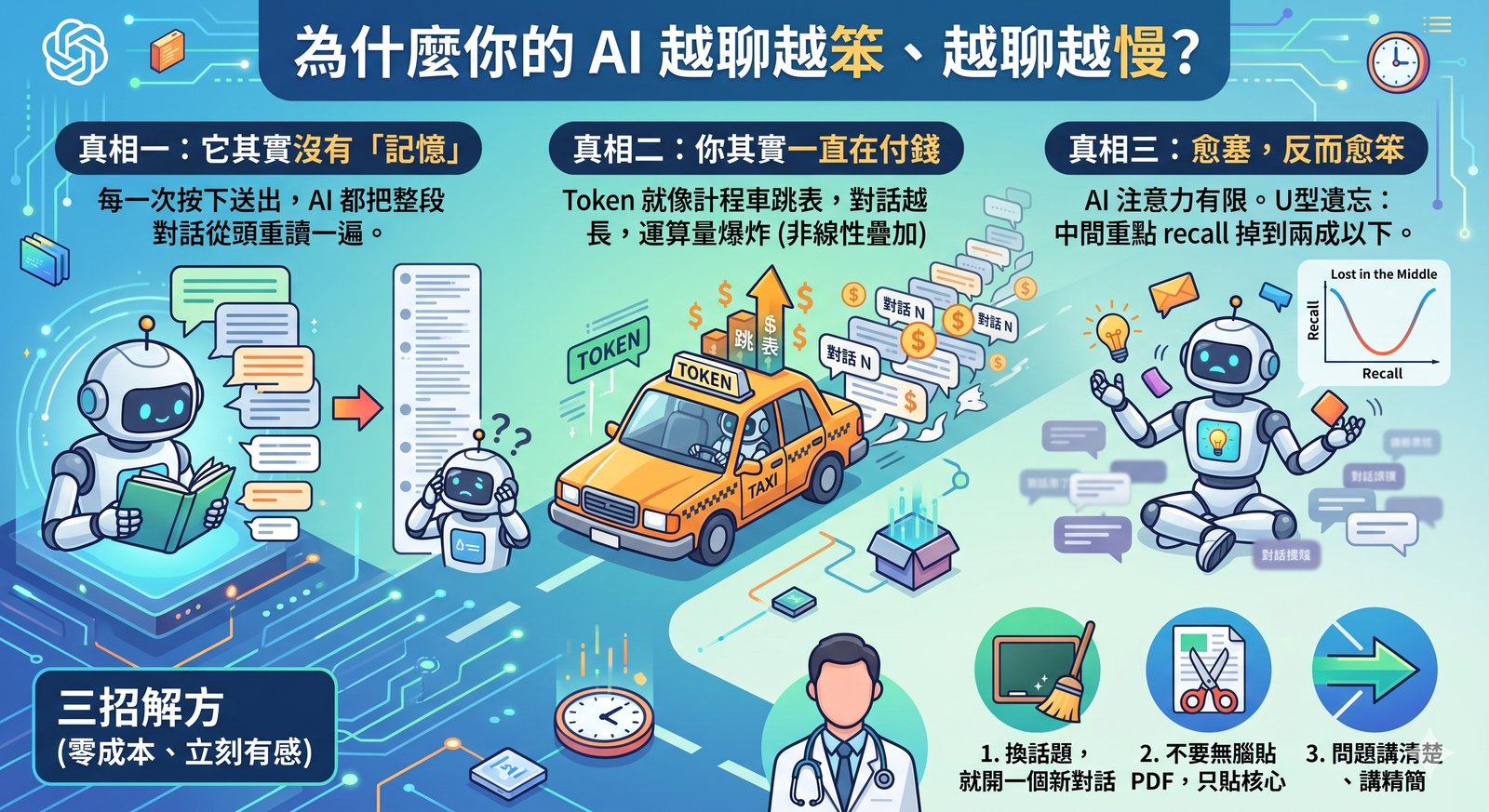
前陣子分享的論文評讀工具(讓 Claude 幫忙做品質評讀跟內容整理),有朋友回我一句很實在的話:工具是好用,但每次都得自己先去把 PDF 生出來,最煩的其實是這一步。 真的是這樣。要讓 AI 幫你讀論文,你得先拿得到全文。而拿全文這件事,卡住的通常不是 AI,是權限、是出版社、是圖書館。 所以論文三件組裡最後一塊、也是最痛的一塊,今天終於補上了:paper-fetch(MIT 開源)。給它一個 DOI,它會自己走完整條路,把全文 PDF 抓下來。 階段 工具 做什麼 發現 論文學習雷達 paper-radar RSS/PubMed 餵新論文,依興趣排序 下載 paper-fetch DOI → 全文 PDF 評讀 paper-review-and-digest 品質評讀、內容整理 — 它怎麼運作?一道由便宜到麻煩的階梯 整個設計只有一句話:先走最便宜、最正當的路,失敗才往下掉。 第一層:開放取用(open access) Unpaywall、Semantic Scholar、PMC/Europe PMC,還有藏在文章網頁裡的 citation_pdf_url meta tag(那正是 Google Scholar 拿來索引 PDF 的東西)。這層零金鑰、開箱即用,你只要在設定檔填自己的 email。沒有圖書館資源的人,能接的來源我都接上去了。 第二層:出版社官方的文字探勘 API(text-mining API) Elsevier、Wiley、Springer 都有正式開放給文字探勘用的 API,自己去申請一把金鑰就好,是完全被允許的管道。這層跟盜版一點關係都沒有,只是大家很少知道它存在。 第三層:自己醫院圖書館的校外連線 用你自己的帳號登入,抓你們醫院本來就有訂的期刊。它只是把你原本會手動做的那一串點擊自動化,不是繞過付費牆。 第四層:投降,但投降得有用 全部失敗的話,它會把圖書館的 SFX/OpenURL 連結印出來讓你手動去點,而不是丟一個 error 就沒了。 沒有 Sci-Hub,沒有盜版路線。 每一層都是你本來就有資格走的路。 — 最花時間的是什麼?把每一家出版社的脾氣摸清楚 這是我覺得整個專案最值得分享的部分。DOI 換 PDF 聽起來像一行程式,實際上每家出版社的做法都不一樣,而且沒有文件可以查,只能一篇一篇撞出來。目前摸清楚、而且用真實文章驗證過的有 20 幾條路線,收斂成四種形狀。 ...